Chapter 4: Syntax
Introduction
Syntax is the linguistic discipline interested in modeling how words are arranged together to make larger sequences in a language. Whereas morphology describes the structure of words internally, syntax describes how words come together to make phrases and sentences.
Morphology and syntax
The relationship between morphology and syntax can be complex especially for morphologically rich languages where many syntactic phenomena are expressed not only in terms of word order but also morphology. For example, Arabic subjects of verbs have a nominative case and adjectival modifiers of nouns agree with the case of the noun they modify. Arabic rich morphology allows it to have some degree of freedom in word order since the morphology can express some syntactic relations.
However, as in many other languages, the actual usage of Arabic is less free, in terms of word order, than it can be in principle.
Part-of-speech
Words are traditionally grouped into equivalence classes called parts of speech (POS), word classes, morphological classes, or lexical tags. In traditional grammars there were generally only a few parts of speech (noun, verb, adjective, preposition, adverb, conjunction, etc.).
More recent models have much larger numbers of word classes (45 for the Penn Treebank, 87 for the Brown corpus, and 146 for the C7 tagset).
The part of speech for a word gives a significant amount of information about the word and its neighbors. This is clearly true for major categories, (verb versus noun), but is also true for the many finer distinctions.
- Parts of speech can be used in stemming for informational retrieval (IR), since knowing a word's part of speech can help tell us which morphological affixes it can take.
- They can also help an IR application by helping select out nouns or other important words from a document.
- Automatic part-of-speech taggers can help in building automatic word-sense disambiguating algorithms,
- and POS taggers are also used in advanced ASR language models such as class-based N-grams,
- Parts of speech are very often used for 'partial parsing' texts, for example for quickly finding names or other phrases for the information extraction applications.
- Finally, corpora that have been marked for part-of-speech are very useful for linguistic research, for example to help find instances or frequencies of particular constructions in large corpora.
Closed and open classes
Parts of speech can be divided into two broad super categories: closed class types and open class types.
- Closed classes are those that have relatively fixed membership. For example, prepositions are a closed class because there is a fixed set of them in English; new prepositions are rarely coined.
- By contrast nouns and verbs are open classes because new nouns and verbs are continually coined or borrowed from other languages (e.g. the new verb to fax or the borrowed noun futon).
It is likely that any given speaker or corpus will have different open class words, but all speakers of a language, and corpora that are large enough, will likely share the set of closed class words.
Closed class words are generally also function words; function words are grammatical words like of, it, and, or you, which tend to be very short, occur frequently, and play an important role in grammar.
There are four major open classes that occur in the languages of the world: nouns, verbs, adjectives, and adverbs. It turns out that English has all four of these, although not every language does. Many languages have no adjectives. In the native American language Lakhota, for example, and also possibly in Chinese, the words corresponding to English adjectives act as a subclass of verbs.
Formal grammars for natural language parsing
In natural language parsing, several formal grammars are commonly used to describe the syntax of natural languages. Some of the main ones include:
Context-Free Grammar (CFG): Perhaps the most widely used formalism in natural language parsing, CFG consists of a set of production rules that describe the syntactic structure of a language. It's used in many parsing algorithms like the CYK algorithm and chart parsers.
Dependency Grammar (DG): DG represents the syntactic structure of a sentence in terms of binary asymmetric relations between words, where one word (the head) governs another (the dependent). It's especially useful for languages with relatively free word order.
Lexical Functional Grammar (LFG): LFG is a theory of grammar that describes the syntax and semantics of natural languages. It represents the structure of a sentence using two separate levels: the constituent structure and the functional structure.
Head-Driven Phrase Structure Grammar (HPSG): HPSG is a grammar framework that describes the syntax of natural languages in terms of a hierarchy of phrases. It's characterized by the idea that every phrase has a head, which determines the syntactic and semantic properties of the phrase.
Tree-Adjoining Grammar (TAG): TAG represents the syntactic structure of a sentence in terms of trees, where elementary trees can be combined through tree-adjoining operations to form larger trees. It's known for its ability to capture long-distance dependencies.
Context-free grammar
A commonly used mathematical system for modelling constituent structure in Natural Language is Context-Free Grammar (CFG) which was first defined for Natural Language in (Chomsky 1957) and was independently discovered for the description of the Algol programming language by Backus and Naur.
Context-Free grammars belong to the realm of formal language theory where a language (formal or natural) is viewed as a set of sentences; a sentence as a string of one or more words from the vocabulary of the language and a grammar as a finite, formal specification of the (possibly infinite) set of sentences composing the language under study. Specifically, a CFG consists of four components:
T, the terminal vocabulary: the words of the language being defined
N, the non-terminal vocabulary: a set of symbols disjoint from T
P, a set of productions of the form
a -> b, where a is a non-terminal and b is a sequence of one or more symbols from \( T \cup N \)S, the start symbol, a member from N
A language is then defined via the concept of derivation and the
basic operation is that of rewriting one sequence of symbols into
another. If a -> b is a
production, we can rewrite any sequence of symbols which contains the
symbol a, replacing a by b. We denote this rewrite operation by the
symbol ==> and read u a v ==> u b v as: u b v directly derives from u a v or conversely, u a v directly produces/generates u b v. For instance, given the grammar G1
S -> NP VP
NP -> PN
VP -> Vi
PN -> Ali
Vi -> runsthe following rewrite steps are possible:
(D1) S ==> NP VP ==> PN VP ==> PN Vi ==> Ali Vi ==> Ali runswhich can be captured in a tree representation called a parse tree e.g.,:
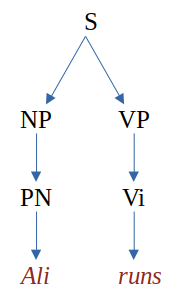
So Ali runs is a sentence of the language defined by G1.
More generally, the language defined by a CFG is the set of terminal
strings (sequences composed entirely of terminal symbols) which can be
derived by a sequence of rewrite steps from the start symbol S.
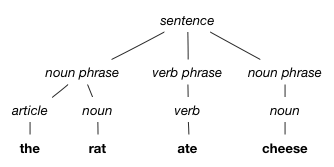
Another example for the English sentence "the rat ate cheese"
A third example drawn from Pennsylvania Arabic Tree Bank (PATB) for the Arabic sentence "خمسون ألف سائح زاروا لبنان وسوريا في أيلول الماضي "

NB. As you can notice the parse tree depends on the grammar. Try to find the grammar for the two later examples.
Parsing
A CFG only defines a language. It does not say how to determine whether a given string belongs to the language it defines. To do this, a parser can be used whose task is to map a string of words to its parse tree.
When proceeding through the search space created by the set of parse trees generated by a CFG, a parser can work either top-down or bottom-up. A top-down parser builds the parse tree from the top, working from the start symbol towards the string.
The example derivation D1
given above illustrates a top-down parsing process: starting from the
symbol S, productions are applied to rewrite a symbol in the generated
string until the input string is derived.
By contrast, a bottom-up
parser starts from the input string and applies productions in reverse
until the start symbol is reached. So for instance, assuming a
depth-first traversal of the search space and a left-to-right processing
of the input string, a bottom up derivation of Ali runs given the grammar G1 would be:
Ali runs ==> PN runs ==> PN Vi ==> NP Vi ==> NP VP==> SCYK algorithm
Cocke–Younger–Kasami (CYK) algorithm is a parsing algorithm for context free grammar. In order to apply CYK algorithm to a grammar, it must be in Chomsky Normal Form. It uses a dynamic programming algorithm to tell whether a string is in the language of a grammar.
Algorithm :
Let w be the n length string to be parsed. And G represent the set of rules in our grammar with start state S.
- Construct a table DP for size n × n.
- If w = \( \epsilon \) (empty string) and S -> \( \epsilon \) is a rule in G then we accept the string else we reject.
For i = 1 to n: For each variable A: We check if A -> b is a rule and b = wi for some i: If so, we place A in cell (i, i) of our table.For l = 2 to n: For i = 1 to n-l+1: j = i+l-1 For k = i to j-1: For each rule A -> BC: We check if (i, k) cell contains B and (k + 1, j) cell contains C: If so, we put A in cell (i, j) of our table.We check if S is in (1, n): If so, we accept the string Else, we reject.