Chapter 2: Processing levels
1. Introduction
Work in natural language processing has tended to view the process of language analysis as being decomposable into a number of stages, mirroring the theoretical linguistic distinctions drawn between SYNTAX, SEMANTICS, and PRAGMATICS.
The simple view is that the sentences of a text are first analyzed in terms of their syntax; this provides an order and structure that is more amenable to an analysis in terms of semantics, or literal meaning; and this is followed by a stage of pragmatic analysis whereby the meaning of the utterance or text in context is determined.
This last stage is often seen as being concerned with DISCOURSE, whereas the previous two are generally concerned with sentential matters.
Such a separation serves as a useful pedagogic aid, and also constitutes the basis for architectural models that make the task of natural language analysis more manageable from a software engineering point of view.
In case the language data can be in speech, another step is necessary to convert it into a suitable form (text) for the subsequent stages.
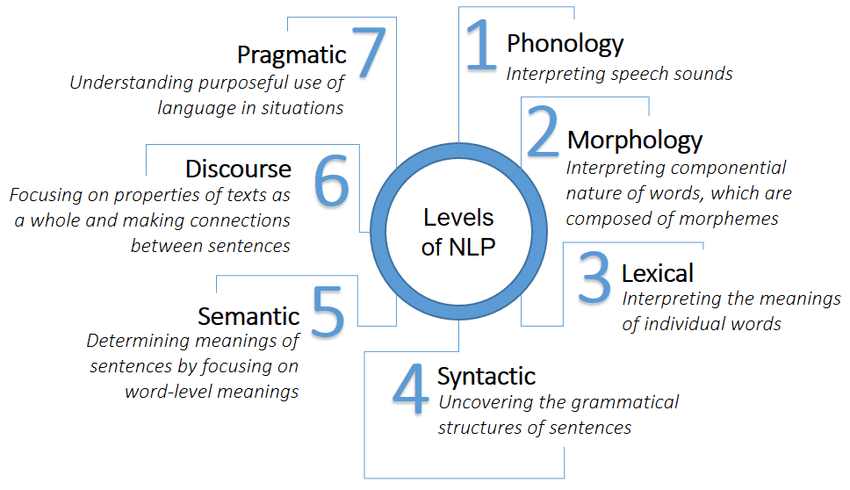
2. Processing levels of NLP
2.1 Phonology and phonetics
This level deals with the interpretation of speech sounds within and across words. There are, in fact, three types of rules used in phonological analysis:
- phonetic rules: for sounds within words;
- phonemic rules: for variations of pronunciation when words are spoken together, and;
- prosodic rules: for fluctuation in stress and intonation across a sentence.
2.2 Morphology and lexical
This level deals with the componential nature of words, which are composed of morphemes: the smallest units of meaning.
For example, the word preregistration can be morphologically analyzed into three separate morphemes: the prefix pre, the root registra, and the suffix tion.
Since the meaning of each morpheme remains the same across words, humans can break down an unknown word into its constituent morphemes in order to understand its meaning.
Similarly, an NLP system can recognize the meaning conveyed by each morpheme in order to gain and represent meaning.
For example,
adding the suffix ed to a verb, conveys that the action of the verb took place in the past.
This is a key piece of meaning, and in fact, is frequently only evidenced in a text by the
use of the ed morpheme.
2.3 Lexical
At this level, humans, as well as NLP systems, interpret the meaning of individual words. Several types of processing contribute to word-level understanding:
- the first of these being assignment of a single part-of-speech tag to each word. In this processing, words that can function as more than one part-of-speech are assigned the most probable part-of-speech tag based on the context in which they occur;
- Additionally at the lexical level, those words that have only one possible sense or
meaning can be replaced by a semantic representation of that meaning. The nature of the
representation varies according to the semantic theory utilized in the NLP system.
Example:
The
following representation of the meaning of the word launch is in the form of logical
predicates.
launch (a large boat used for carrying people on rivers, lakes harbors, etc.)
(
(CLASS BOAT) (PROPERTIES (LARGE) (PURPOSE (PREDICATION (CLASS CARRY) (OBJECT PEOPLE)))
)
As can be observed, a single lexical unit is decomposed into its more basic properties. Given that there is a set of semantic primitives used across all words, these simplified lexical representations make it possible to unify meaning across words and to produce complex interpretations, much the same as humans do.
The lexical level may require a lexicon, and the particular approach taken by an NLP system will determine whether a lexicon will be utilized, as well as the nature and extent of information that is encoded in the lexicon. Lexicons may be quite simple, with only the words and their part(s)-of-speech, or may be increasingly complex and contain information on the semantic class of the word, what arguments it takes, and the semantic limitations on these arguments, definitions of the sense(s) in the semantic representation utilized in the particular system, and even the semantic field in which each sense of a polysemous word is used.
2.4 Syntax
This level focuses on analyzing the words in a sentence so as to uncover the grammatical structure of the sentence. This requires both a grammar and a parser. The output of this level of processing is a (possibly delinearized) representation of the sentence that reveals the structural dependency relationships between the words. There are various grammars that can be utilized, and which will, in turn, impact the choice of a parser. Not all NLP applications require a full parse of sentences, therefore the remaining challenges in parsing of prepositional phrase attachment and conjunction scoping no longer stymie those applications for which phrasal and clausal dependencies are sufficient. Syntax conveys meaning in most languages because order and dependency contribute to meaning.
For example the two sentences: ‘The dog chased the cat.’ and ‘The cat chased
the dog.’ differ only in terms of syntax, yet convey quite different meanings.
To get a grasp of the fundamental problems discussed here, it is instructive to consider the ways in which parsers for natural languages differ from parsers for computer languages.
- One such difference concerns the power of the grammar formalisms used: the generative capacity. Computer languages are usually designed so as to permit encoding by unambiguous grammars and parsing in linear time of the length of the input.
To this end, carefully restricted subclasses of context-free grammar (CFG) are used, with the syntactic specification of ALGOL 60 as a historical exemplar. In contrast, natural languages are typically taken to require more powerful devices, as first argued by Chomsky (1956). One of the strongest cases for expressive power has been the occurrence of long-distance dependencies, as in English wh-questions.
- A second difference concerns the extreme structural ambiguity of natural language. At any point in a pass through a sentence, there will typically be several grammar rules that might apply. A classic example is the following:
Put the block in the box on the table.
Assuming that “put” subcategorizes for two objects, there are two possible analyses:
- Put the block [in the box on the table].
- Put [the block in the box] on the table.
2.5 semantics
This is the level at which most people think meaning is determined, however, as we can see in the above defining of the levels, it is all the levels that contribute to meaning. Semantic processing determines the possible meanings of a sentence by focusing on the interactions among word-level meanings in the sentence.
This level of processing can include the semantic disambiguation of words with multiple senses; in an analogous way to how syntactic disambiguation of words that can function as multiple parts-of-speech is accomplished at the syntactic level.
Semantic disambiguation permits one and only one sense of polysemous words to be selected and included in the semantic representation of the sentence.
For example, amongst other meanings, ‘file’ as a noun can mean either:
- a folder for storing papers,
- or a tool to shape one’s fingernails,
- or a line of individuals in a queue.
If information from the rest of the sentence were required for the disambiguation, the semantic, not the lexical level, would do the disambiguation.
A wide range of
methods can be implemented to accomplish the disambiguation, some which require
information as to the frequency with which each sense occurs in a particular corpus of
interest, or in general usage, some which require consideration of the local context, and
others which utilize pragmatic knowledge of the domain of the document.
2.6 Discourse
While syntax and semantics work with sentence-length units, the discourse level of NLP works with units of text longer than a sentence. That is, it does not interpret multi sentence texts as just concatenated sentences, each of which can be interpreted singly.
Rather, discourse focuses on the properties of the text as a whole that convey meaning by making connections between component sentences.
- Several types of discourse processing can occur at this level, two of the most common being anaphora resolution and discourse/text structure recognition.
- Anaphora resolution is the replacing of words such as pronouns, which are semantically vacant, with the appropriate entity to which they refer. Discourse/text structure recognition determines the functions of sentences in the text, which, in turn, adds to the meaningful representation of the text.
- For example, newspaper articles can be deconstructed into discourse components such as: Lead, Main Story, Previous Events, Evaluation, Attributed Quotes, and Expectation.
2.7 Pragmatics
This level is concerned with the purposeful use of language in situations and utilizes context over and above the contents of the text for understanding. The goal is to explain how extra meaning is read into texts without actually being encoded in them. This requires much world knowledge, including the understanding of intentions, plans, and goals.
Some NLP applications may utilize knowledge bases and inferencing modules.
For
example, the following two sentences require resolution of the anaphoric term ‘they’, but
this resolution requires pragmatic or world knowledge.
- The city councilors refused the demonstrators a permit because they feared violence.
- The city councilors refused the demonstrators a permit because they demanded a ceasefire.
3. NL Understanding vs NL Generation
The processing in language understanding/comprehension (NLU) typically follows the traditional stages of a linguistic analysis:
- phonology,
- morphology,
- syntax,
- semantics,
- pragmatics/discourse;
The primary process involves scanning the words of the text in sequence, during which the form of the text gradually unfolds. The need to scan imposes a methodology based on the management of multiple hypotheses and predictions that feed a representation that must be expanded dynamically.
Major problems are caused by ambiguity (one form can convey a range of alternative meanings), and by under-specification (the audience gets more information from inferences based on the situation than is conveyed by the actual text).
In addition, mismatches in the speaker’s and audience’s model of the situation (and especially of each other) lead to unintended inferences.

Generation (NLG) has the opposite information flow: from intentions (meaning) to text, content to form.
What is already known and what must be discovered is quite different from NLU, and this has many implications. The known is the generator’s awareness of its speaker’s intentions and mood, its plans, and the content and structure of any text the generator has already produced.
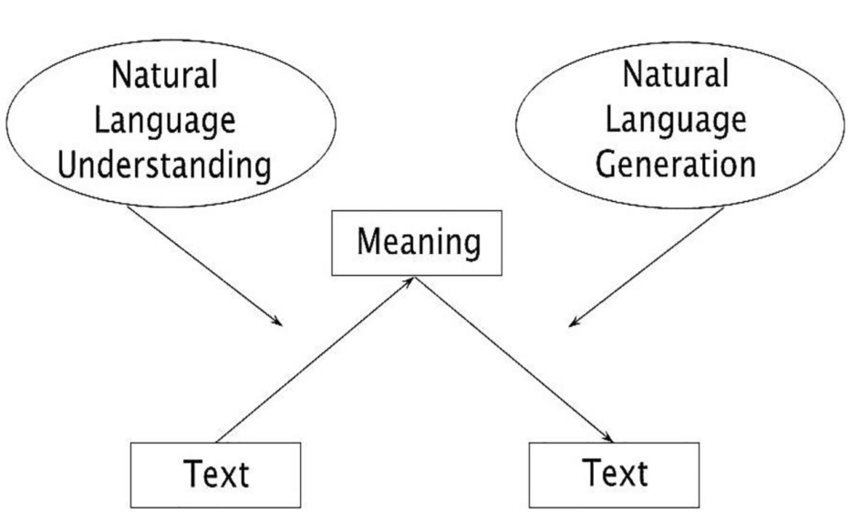
Coupled with a model of the audience, the situation, and the discourse, this information provides the basis for making choices among the alternative wordings and constructions that the language provides—the primary effort in deliberately constructing a text.
Most generation systems do produce texts sequentially from left to right, but only after having made decisions top-down for the content and form of the text as a whole. Ambiguity in a generator’s knowledge is not possible (indeed one of the problems is to notice that an ambiguity has inadvertently been introduced into the text).
Rather than under-specification, a generator’s problem is how to choose how to signal its intended inferences from an oversupply of possibilities along with that what information should be omitted and what must be included.
With its opposite flow of information, it would be reasonable to assume that the generation process can be organized like the comprehension process but with the stages in opposite order, and to a certain extent this is true: pragmatics (goal selection) typically precedes consideration of discourse structure and coherence, which usually precede semantic matters such as the fitting of concepts to words. In turn, the syntactic context of a word must be fixed before the precise morphological and suprasegmental form it should take can be known. However, we should avoid taking this as the driving force in a generator’s design, since to emphasize the ordering of representational levels derived from theoretical linguistics would be to miss generation’s special character, namely, that generation is above all a planning process.
Generation entails realizing goals in the presence of constraints and dealing with the implications of limitations on resources.