NLP Applications
4. NLP applications
There are two main categories of NLP applications. It depends on the amount of processing and depth of processing levels as well as the linguistic resources needed to accomplish such applications.
An application can be light and fast which does not require in-depth processing of linguistic data and can also be heavy when it needs to go through several processes one after the other to achieve its objective.
4.1. Heavy NLP applications
4.1.1. Machine translation
Machine translation (MT) technology enables the conversion of text or speech from one language to another using computer algorithms.
In fields such as marketing or technology, machine translation enables website localization, enabling businesses to reach wider clientele by translating their websites into multiple languages. Furthermore, it facilitates multilingual customer support, enabling efficient communication between businesses and their international customers. Machine translation is used in language learning platforms to provide learners with translations in real time and improve their understanding of foreign languages. Additionally, these translation services have made it easier for people to communicate across language barriers.

MT works with large amounts of source and target languages that are compared and matched against each other by a machine translation engine. We differentiate three types of machine translation methods:
- Rules-based machine translation uses grammar and language rules, developed by language experts, and dictionaries which can be customized to a specific topic or industry.
- Statistical machine translation does not rely on linguistic rules and words; it learns how to translate by analyzing large amount of existing human translations.
- Neural machine translation teaches itself on how to translate by using a large neural network. This method is becoming more and more popular as it provides better results with language pairs.
4.1.2. Text summarization
Automatic text summarization, or just text summarization, is the process of creating a short and coherent version of a longer document. The ideal of automatic summarization work is to develop techniques by which a machine can generate summarize that successfully imitate summaries generated by human beings.
It is not enough to just generate words and phrases that capture the gist of the source document. The summary should be accurate and should read fluently as a new standalone document.

There are many reasons and use cases for a summary of a larger document.
- headlines (from around the world)
- outlines (notes for students)
- minutes (of a meeting)
- previews (of movies)
- synopses (soap opera listings)
- reviews (of a book, CD, movie, etc.)
- digests (TV guide)
- biography (resumes, obituaries)
- abridgments (Shakespeare for children)
- bulletins (weather forecasts/stock market reports)
- sound bites (politicians on a current issue)
- histories (chronologies of salient events)
There are two main approaches to summarizing text documents; they are:
Extractive Methods: extractive text summarization involves the selection of phrases and sentences from the source document to make up the new summary. Techniques involve ranking the relevance of phrases in order to choose only those most relevant to the meaning of the source.
Abstractive Methods: abstractive text summarization involves generating entirely new phrases and sentences to capture the meaning of the source document. This is a more challenging approach, but is also the approach ultimately used by humans. Classical methods operate by selecting and compressing content from the source document.
4.1.3. Information extraction
An example of information extraction is the extraction of instances of corporate mergers. For example, the following string might result in an online-news sentence such as Yesterday, New-York based Foo Inc. announced their acquisition of Bar Corp.:
MergerBetween(company1,company2,date)
The significance of IE is determined by the growing amount of information that is available in unstructured form, this means without metadata, for example, on the Internet. You can better access unstructured information by transforming it into relational form.
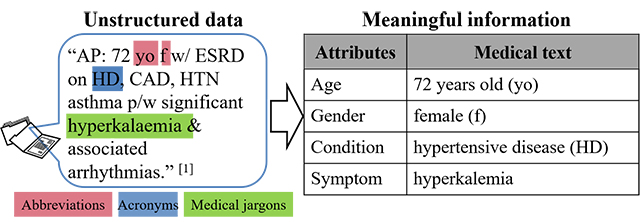
A typical application of IE is to scan a set of documents that is written in a natural language and populate a database with the extracted information.
Following subtasks are typical for IE:
- Named entity recognition: recognition of entity names, for example, for people or organizations, product names, location names, temporal expressions, and certain types of numerical expressions.
- References: identification chains of noun phrases that refer to the same object
- Terminology extraction: finding the relevant terms for a given corpus
- Opinion extraction or sentiment extraction: determine the positive or the negative tonality of the text when describing a product, a service, or a person
There are many different algorithms to implement subtasks of information extraction. Each algorithm is suitable for a specific set of business problems:
- Rule-based algorithms use patterns to extract concepts like phone numbers or email-addresses.
- List-based algorithms use an enumeration of words to extract concepts like person names, product names, or location names.
- More advanced algorithms use natural language processing, machine learning, statistical approaches, or a combination of these to extract complex concepts like sentiment or tonality.
4.1.4. Information retrieval
Documents can be indexed by both the words they contain, as well as the concepts that can be matched to domain-specific thesauri; concept matching, however, poses several practical difficulties that make it unsuitable for use by itself.
Due to the spread of the World Wide Web, IR is now mainstream because most of the information on the Web is textual. Web search engines such as Google and Yahoo are used by millions of users to locate information on Web pages across the world on any topic. The use of search engines has spread to the point where, for people with access to the Internet, the World Wide Web has replaced the library as the reference tool of first choice. The information retrieval system is based on document indexing.
What is Document Indexing?
There are several ways to pre-process documents electronically so as to speed up their retrieval. All of these fall under the general term ‘indexing’: an index is a structure that facilitates rapid location of items of interest, an electronic analog of a book’s index.
The most widely used technique is word indexing, where the entries (or terms) in the index are individual words in the document (ignoring ‘stop words’—very common and uninteresting words such as ‘the’, ‘an’, ‘of’, etc).
Another technique is concept indexing, where one identifies words or phrases and tries to map them to a thesaurus of synonyms as concepts. Therefore, the terms in the index are concept IDs.
Several kinds of indexes are created.
- The global term-frequency index records how many times each distinct term occurs in the entire document collection.
- The document term-frequency index records how often a particular term occurs in each document.
- An optional proximity index records the position of individual terms within the document as word, sentence or paragraph offsets.
4.1.5. Question answering system
Question-answering research attempts to develop ways of answering a wide range of question types, including fact, list, definition, how, why, hypothetical, semantically constrained, and cross-lingual questions.
- Answering questions related to an article in order to evaluate reading comprehension is one of the simpler form of question answering, since a given article is relatively short compared to the domains of other types of question-answering problems. An example of such a question is "What did Albert Einstein win the Nobel Prize for?" after an article about this subject is given to the system.
- Closed-book question answering is when a system has memorized some facts during training and can answer questions without explicitly being given a context. This is similar to humans taking closed-book exams.
- Closed-domain question answering deals with questions under a specific domain (for example, medicine or automotive maintenance) and can exploit domain-specific knowledge frequently formalized in ontologies. Alternatively, "closed-domain" might refer to a situation where only a limited type of questions are accepted, such as questions asking for descriptive rather than procedural information. Question answering systems in the context of machine reading applications have also been constructed in the medical domain, for instance related to Alzheimer's disease.
- Open-domain question answering deals with questions about nearly anything and can only rely on general ontologies and world knowledge. Systems designed for open-domain question answering usually have much more data available from which to extract the answer. An example of an open-domain question is "What did Albert Einstein win the Nobel Prize for?" while no article about this subject is given to the system.
4.1.5. Image captioning
Image captioning—the task of providing a natural language description of the content within an image—lies at the intersection of computer vision and natural language processing.

As both of
these research areas are currently highly active and have experienced many recent advances, progress in
image captioning has naturally followed suit. On the computer vision side, improved convolutional
neural network and object detection architectures have contributed to improved image captioning
systems. On the natural language processing side, more sophisticated sequential models, such as
attention-based recurrent neural networks, have similarly resulted in more accurate caption generation.
Inspired by neural machine translation, most conventional image captioning systems utilize an
encoder-decoder framework, in which an input image is encoded into an intermediate representation
of the information contained within the image, and subsequently decoded into a descriptive text
sequence. This encoding can consist of a single feature vector output of a CNN, or
multiple visual features obtained from different regions within the image. In the latter case, the
regions can be uniformly sampled, or guided by an object detector which has
been shown to yield improved performance.
4.2. Light NLP applications
4.2.1. Spell/grammar checking/correction
4.2.2 Spam detection
4.2.3 Text classification
4.2.4 Text prediction
4.2.5 Named entity recognition